ClearSCADA can calculate the standard deviation value for a sample of historic values. Standard deviation is a commonly used statistical calculation that is used to measure the spread of values over a time period. It is useful when investigating patterns in data as the standard deviation results use the same base units as the raw historic values in the sample, which means it easier to determine the statistical significance of the values.
The standard deviation algorithm complies with the OPC standard, which defines the calculation as:

Where:
- X is each good quality raw historic value in the sample
- Avg(X) is the mean average value of the good quality raw historic values in the sample
- n is the number (quantity) of good quality raw historic values in the sample.
As part of the standard deviation calculation, ClearSCADA calculates the average value of the values in the sample. The result of the standard deviation calculation is indicative of the amount of variance between the actual raw historic values in the sample and the average value of the raw historic values. This means that the larger the range of values in the sample, the greater the standard deviation value for the sample will be. Therefore, high standard deviation values often indicate unusual changes in the data source’s values, for example, a sudden trough of low values, peak of high values, or erratic changing between high and low values.
For example, on a Trend you can configure a processed historic trace to use the Std Dev algorithm and have an Interval of 1M. This would result in ClearSCADA calculating the standard deviation value for every minute (each sample contains 1 minute’s worth of raw historic data).
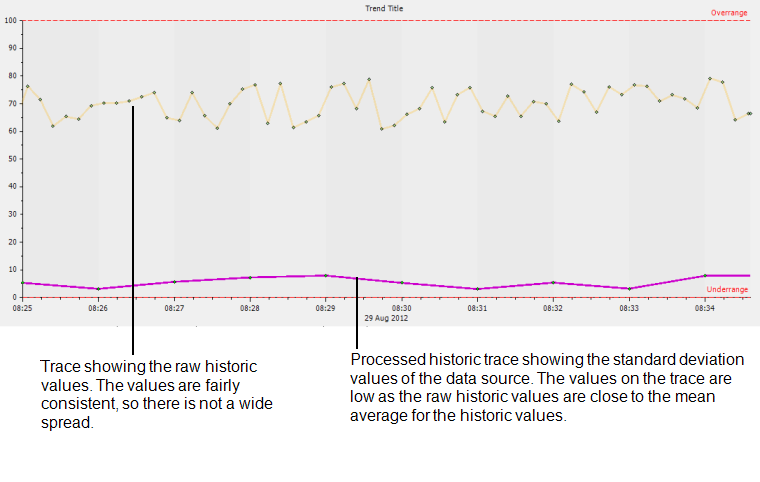
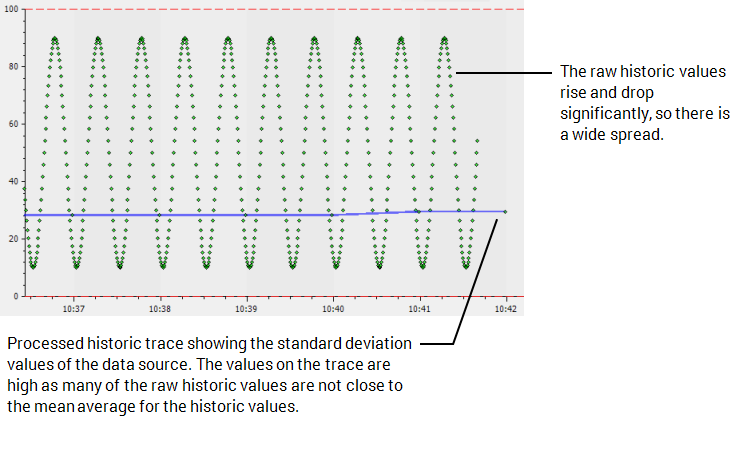
In ClearSCADA, the timestamp for each Std Dev result is the start time of the sample. For example, if the sample starts at 01:00 and ends at 01:10, ClearSCADA would use the raw historic values for the period 01:00 to 01:10 in its calculation, then return the standard variant value with a timestamp of 01:00.
The standard deviation value for each sample uses the same units as the data source.